HashTable in Rust from Scratch
Recently, I wanted to revisit Rust, and while following along with the book Crafting Interpreters, I came across the chapter on implementing a Hash Table. I discovered many interesting details about Hash Table implementations, which inspired me to write this blog post. I will implement a Hash Table using Rust and conduct some possibly non-standard benchmarks.
A Hash Table typically consists of two main components:
- A hash function
- A collision resolution strategy, commonly including: a. Chaining b. Linear probing
In our Hash Table, we will use String as the key type and a simple hash function called FNV-1a to compute the hash value. To avoid recalculating the hash value on each query, we will precompute and cache it within the key.
pub struct KeyValue {
key: Key,
value: Value,
}
pub struct Key {
name: String,
hash: u32,
}
impl Key {
pub fn new(name: &str) -> Self {
let mut hash: u32 = 2166136261u32;
for &b in name.as_bytes() {
hash ^= b as u32;
hash = hash.wrapping_mul(16777619);
}
Self {
name: name.to_string(),
hash,
}
}
}
pub enum Value {
Boolean(bool),
Number(f64),
String(String),
}
A Hash Table requires an array as storage space, and it must also keep track of how many entries are currently stored in the array to facilitate space expansion when it approaches capacity.
pub struct Table {
pub count: usize,
entries: Vec<Entry>,
}
pub enum Entry {
KeyValue(KeyValue),
Tombstone,
None,
}
The entries array is where the actual data is stored, and each element is an enum with three possible states: the first indicates data is present, the second indicates the data has been deleted, and the third indicates no data exists. A Tombstone is a common technique used to implement the delete operation in a Hash Table. If the Hash Table uses chaining to resolve collisions, the delete operation is straightforward; you simply remove the corresponding element from the chain. However, to reduce the probability of CPU cache misses, we will use linear probing for our implementation.
Unlike chaining, when a collision occurs, linear probing searches the array to find the first available space to store the element. During lookups, if the target key is not found at the desired index, it continues to search sequentially until it encounters an empty element or finds the target key.
However, the delete operation in linear probing is relatively challenging to implement. Imagine if we simply remove an element, it introduces an empty slot, which could break the “chain” of other key lookups. A tombstone provides a solution by replacing the element to be deleted with a tombstone. When a lookup encounters a tombstone, it continues searching, thus preserving the “chain.” When inserting, if a tombstone is encountered, it is simply replaced, avoiding wasting space.
Before implementing insert, lookup, and delete operations, we define a helper function, find_entry, which is responsible for searching for a specified key. If found, it returns the corresponding index; if not found, it returns an index where the key can be inserted. This insertable index may correspond to either an empty element or a tombstone.
enum FindResult {
Found(usize),
Available(usize),
Tombstone(usize),
}
fn find_entry(entries: &Vec<Entry>, key: &Key) -> FindResult {
let mut index = (key.hash % entries.len() as u32) as usize;
let mut tombstone: Option<FindResult> = None;
loop {
match &entries[index] {
Entry::KeyValue(kv) => {
if kv.key == *key {
return FindResult::Found(index);
}
}
Entry::Tombstone => {
if tombstone.is_none() {
tombstone = Some(FindResult::Tombstone(index))
}
}
Entry::None => {
if tombstone.is_some() {
return tombstone.unwrap();
}
return FindResult::Available(index);
}
}
index = (index + 1) % entries.len();
}
}
Next, we will implement the lookup operation get. Since we already have find_entry, implementing the lookup becomes very straightforward.
impl Table {
pub fn get(&self, key: &Key) -> Option<Value> {
if self.entries.len() == 0 {
return None;
}
if let FindResult::Found(entry_index) = find_entry(&self.entries, &key) {
if let Entry::KeyValue(kv) = &self.entries[entry_index] {
return Some(kv.value.clone());
}
}
return None;
}
}
The insert operation set is a bit more complex than lookup because there might be insufficient space in the array during insertion. To optimize performance, we cannot wait until the space is nearly full to expand it. As the available space decreases, the probability of collisions increases, leading to longer lookup times. Therefore, we define a MAX_LOAD threshold, indicating when the used space reaches a certain ratio, prompting space expansion.
Here, we define another helper function, adjust_capacity, to handle space expansion. Inside this function, we first allocate a larger space and then traverse the original space, inserting existing elements one by one.
impl Table {
fn adjust_capacity(&mut self, capacity: usize) {
let mut entries: Vec<Entry> = vec![Entry::None; capacity];
self.count = 0;
for e in &self.entries {
if let Entry::KeyValue(entry) = e {
if let FindResult::Available(index) = find_entry(&mut entries, &entry.key) {
entries[index] = Entry::KeyValue(entry.clone());
self.count += 1
}
}
}
self.entries = entries;
}
}
With adjust_capacity implemented, we can now implement the set operation. First, we check whether inserting will exceed the load threshold. If it does, we expand the space (I arbitrarily chose a strategy: if the length is less than 8, expand it to 8 directly; otherwise, double the current length). Then, we use find_entry to determine the index where we can insert the key. If Found is returned, it means the key already exists, so we update it; if Available is returned, it means the key does not exist, and there is an empty slot available, so we increment the element count count and insert the new entry; if Tombstone is returned, we treat the tombstone as an existing element and do not increment count. This is crucial because if we do not consider the tombstone as an existing element, when the array is filled with tombstones and no empty slots remain, find_entry could enter an infinite loop.
impl Table {
const MAX_LOAD: f32 = 0.75;
pub fn set(&mut self, key: &Key, value: &Value) {
if (self.count + 1) as f32 > Self::MAX_LOAD * self.entries.len() as f32 {
let capacity = if self.entries.len() < 8 {
8
} else {
self.entries.len() * 2
};
self.adjust_capacity(capacity);
}
let index = match find_entry(&self.entries, &key) {
FindResult::Found(index) => index,
FindResult::Available(index) => {
self.count += 1;
index
}
FindResult::Tombstone(index) => index,
};
self.entries[index] = Entry::KeyValue(KeyValue {
key: key.clone(),
value: value.clone(),
});
}
}
With the tombstone mechanism in place, implementing the delete operation becomes quite simple; we just replace the corresponding element with a tombstone.
impl Table {
pub fn delete(&mut self, key: &Key) {
if self.count == 0 {
return;
}
if let FindResult::Found(index) = find_entry(&self.entries, &key) {
self.entries[index] = Entry::Tombstone;
}
}
}
Now, we have a complete and functional Hash Table implementation. Let’s perform some benchmarks.
I define an operation that involves inserting a certain number n of elements, then deleting n/10 of those elements, and finally querying n*200 times to calculate the average time taken for each operation.
The results are as follows, where the x-axis represents the number of elements n (from 10 to 1500), and the y-axis represents the average time taken for operations at the current scale. It can be observed that the average time fluctuates in a sawtooth pattern as the scale increases. Each rising segment indicates that, under fixed storage size, the operation times increase as the number of elements stored in the Hash Table increases (indicating more collisions). When the threshold is reached, the space is expanded, and the average operation time drops accordingly.
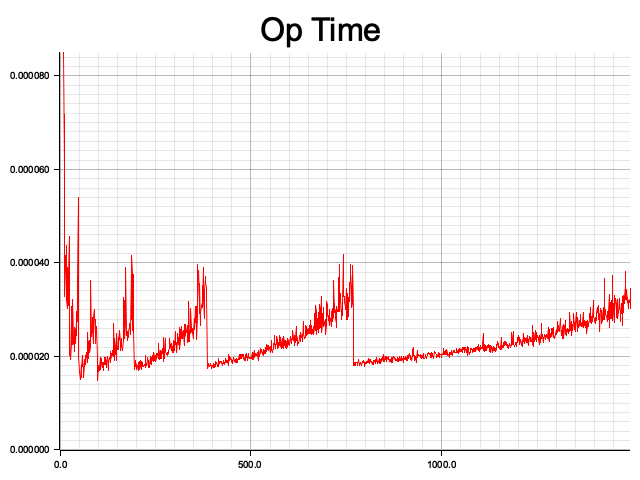
Additionally, I calculated the amortized operation time. Similarly, the x-axis represents the input size, but the y-axis shows the average time taken for all operations up to that point. It can be seen that the amortized time complexity of the Hash Table indeed approaches O(1).
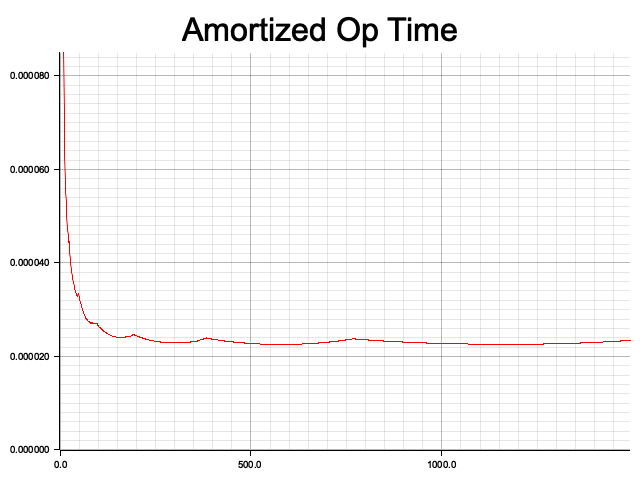
Through this implementation, I gained insights into some unique details of Hash Tables, such as the peculiarities of deletion in linear probing, the pros and cons of different collision resolution algorithms, and the actual time complexity of Hash Tables.
There are many more aspects to discuss regarding Hash Tables, such as comparing the performance of different hash functions, empirically comparing the performance differences of various collision solving algorithms, and exploring algorithmic performance beyond the tombstone mechanism in linear probing. These topics are left for future exploration.